

We are at the cusp of one of the largest technological inflections in our generation. Some industries will be uprooted and replaced; others will grow significantly as new markets are unlocked. With the proper framework, investors can be ready to take advantage of these inflections. This research article is meant as a primer on Generative AI, how it will evolve, and other perspectives.
Generative AI Primer
The rise of Generative AI has ushered in a new era: the mass production of intelligence. Intelligence, unlike the products of previous general-purpose technologies, has unlimited demand. Intelligence drives innovation and efficiency. Chat GPT was the big bang of Generative AI. Within two months, it had 100 million users, making it the fastest growing application in history. VC Investments in Gen AI have increased by almost 400% in 2023, reaching almost $30B. Gen AI and LLMs are in the lexicon of almost every management team today. The appetite for Generative AI-driven workloads, such as large language models (LLMs), is voracious, fueled by continuous demand, such as text-to-video generation.
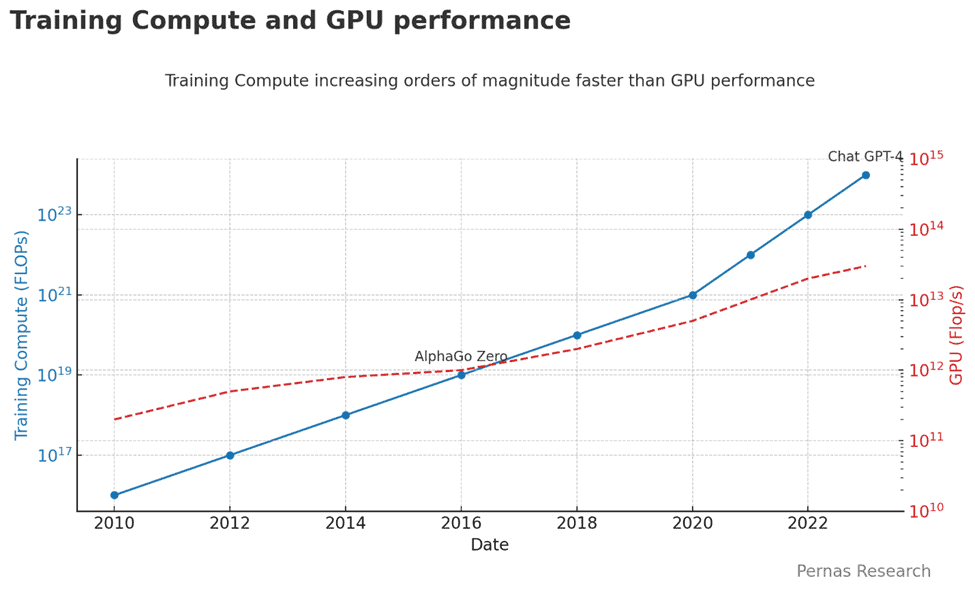
The pivotal question is the pace at which Gen AI will improve. Will it accelerate faster than expected? Will there be another AI winter? Are LLMs an off ramp to intelligent AI? Currently, the acceleration of these models makes Moore’s Law look like its standing still, accelerating at a rate more than 100x that of GPU performance, shown in the graph below. Chat GPT 4 is approximately 1000x larger (by the amount of training computation) than the original model Chat GPT 1, which came out less than two years ago. AI models are growing 1,000X every two to three years due to increased performance the more data they process. We will go into these ‘scaling laws’ in more detail later in the article.
How do LLMs work?
LLMs are prediction machines. They differ from traditional predictive systems, like those used in Google search, which rely on querying a database of similar words and selecting the highest next-word correlation. LLMs on the other hand understand intent and context. They are trained on vast amounts of text data to have this ability. The underpinning architecture of how these models train is called ‘Transformer’. Transformers emphasize the most relevant aspects of text, allowing them to derive proper context through their attention mechanisms. Transformers convert text into numerical representations, or "tokens," assigning weights to these representations based on their importance in making sequence predictions. All of these representations can be thought of as vectors in a very high-dimensional vector space. This architecture includes parameters that can number in the trillions, with each parameter having a specific weight. This architecture enables LLMs to handle and process vast amounts of unstructured data efficiently. When an input is provided, these parameters and their corresponding weights interact to generate an output. As Karpathy succinctly put it, LLMs are a form of “lossy compression”. Chat GPT compressed the entire text corpus of the internet, from around 10 Terabytes into about half a Terabyte. It can answer almost anything a person would ever want to know.
LLMs operate in two main stages: Training followed by Inference. During the training stage, the LLM ingests a vast corpus of unstructured data, learning to predict the next word in a sentence and developing a broad understanding of language. It then undergoes fine-tuning, where its parameters are adjusted using more curated datasets and techniques like Reinforcement Learning from Human Feedback (RLHF) to specialize its responses. RLHF are large teams of people that rate the better answer provided by the LLM, giving it a feedback loop. Once the fine-tuning is complete, the model can perform inference, akin to applying learned knowledge to generate responses. The cost of inference, or the computational expense, is rapidly falling due to more efficient hardware and querying methods. This trend has yielded ChatGPT now offering a limited free version, and other models being completely free.
LLMs are far from perfect, sometimes giving a completely erroneous response to a simple question. LLM error today stems from three factors: Model error, data error, and a certain amount of irreducible error. Thus far, the largest cause of error is data quality.
LLM Error (# of Parameters, Data)= Model error + Data error +Quantum error
Potential Hurdles to Gen AI Improvement
The below factors could be large roadblocks to Gen AI improvements and could precipitate an AI winter.
Compute: The compute necessary to train these models is growing orders of magnitude faster than advancement in GPU processing capability. The solution is either significantly more GPU production or more specialized chips (ASICs) to train these models. Currently, GPU production is constrained by TSMC capacity.
Power: The infrastructure needed to train these models is getting exceedingly larger. Training Chat GPT-4 with 1.7 trillion parameters was a substantial undertaking. It cost about $100 million and used about 60 GWhrs of energy, equivalent to the total energy usage of 70k homes for one month. These are staggering numbers and are transforming the entire data center landscape. Data centers alone could consume almost ten percent of US energy needs by 2030, from around 2% today. Bringing on large new data centers requires access to new power which is held up entirely by regulatory processes. We wrote about the evolution of data centers due to AI here.
Data: The appetite for Data ingestion by Generative AI-driven workloads, such as large language model (LLM) Training, is voracious, almost as voracious as a Quasar, fueled by continuous innovation and applications, like text-to-video generation. The amount of high quality text data is set to be completely used by 2025, named the “data wall”. However there are exabytes of data in the form of videos to offset this as well as the possible use of synthetic data. This is where the LLMs can generate data that it then trains on. This is analogous to DeepMind playing millions of chess games against itself.
Gen AI Architecture:There is a nonzero probability that Transformers …